Определяем требования к решению, ожидания и «боли» вашей сферы. Анализируем бизнес и определяем процессы для автоматизации.
Data Engineering
Закажите бесплатный пилотный проект
Перед началом проекта мы анализируем бизнес-процессы заказчика и по желанию клиента выполняем пилотный проект за наш счет.С КАКИМИ ПРОБЛЕМАМИ СТАЛКИВАЮТСЯ КОМПАНИИ?
Компании используют Корпоративные хранилища (Data Warehouses, DWH) и Data Lakes для сбора и накапливания большого количества информации. Проблема возникает, когда предприятия пытаются объединить неструктурированные и противоречивые данные из разных источников. Данные теряются, дублируются, появляются логические конфликты. Это приводит к снижению качества данных и аналитических отчетов на их основе.
Что такое Data Engineering?
Data Engineering – программирование сбора, хранения, обработки, поиска и визуализации данных.
Data Engineering помогает построить стабильные процессы ETL и ELT добычи и подготовки данных для систем аналитики, алгоритмов машинного обучения, Data Science.
| Качественные данные становятся доступны в нужном виде сотрудникам компании. |
Какие преимущества получают компании?
1/ Прозрачность процессов сбора данных из внешних и внутренних источников, их хранения, обработки и передачи в корпоративные системы.
2/ Актуальные подготовленные данные для систем аналитики, алгоритмов машинного обучения и Data Science
3/ Точные модели аналитики, например, для прогнозирования оттока клиентов, мошенничества и пр.
КАКИЕ СЕРВИСЫ ПРЕДЛАГАЕМ ПРЕДПРИЯТИЯМ?
1/ Внедрение методов интеграции данных
Разрабатываем и внедряем процессы извлечения, трансформации и загрузки данных (процессы ETL и ELT), методы проверки качества и маскирования данных (DQM), проектируем процессы для распределённых вычислений.
2/ Внедрение систем аналитики и визуализации данных
Внедряем системы аналитики, способные обрабатывать текущие данные: формировать отчеты и строить прогнозы. При необходимости настраиваем прескриптивную аналитику, чтобы проверить гипотезы и получить вероятные сценарии развития ситуации.
3/ Разработка DWH, Data Lake
Разрабатываем Data Warehouse и Data Lake на базе решений классических СУБД, СУБД MPP (Multi Parallel Processing) и Big Data (distributed computing).
Решения способны обрабатывать большие объемы информации и потоки данных в режиме реального времени.
4/ Миграция систем в облако
Мигрируем с on-premise в облако как в рамках одного, так и разных вендоров.
ЭКСПЕРТИЗА DATA ENGINEERING В ОБЛАЧНЫХ СЕРВИСАХ
Развертываем и настраиваем инфраструктуру решений в облаке.




DATA ENGINEERING В ИЕРАРХИИ ПОТРЕБНОСТЕЙ ДЛЯ УПРАВЛЕНИЯ ДАННЫМИ
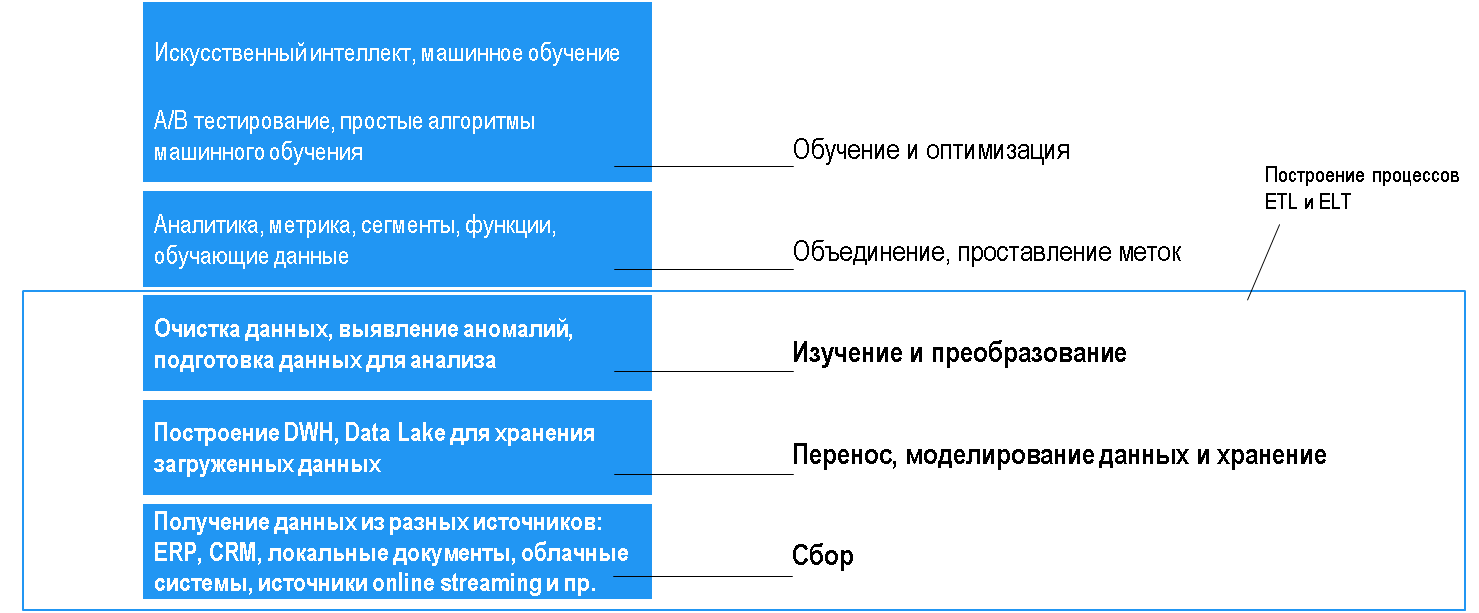
КЛЮЧЕВЫЕ ОТЛИЧИЯ ПРОЦЕССОВ ETL И ELT
ETL-процесс работает с данными, структура которых определяется заранее при моделировании DWH. Трансформация данных происходит в зоне подготовки, и в целевые системы попадает обработанная информация, которая соответствует стандартам, например, GDPR, HIPAA и пр.
При ELT-процессах в Data Lake или целевые системы загружаются любые данные и обрабатываются уже после загрузки. Такой подход дает больше гибкости и упрощает хранение при появлении новых форматов данных.
Этапы процесса ETL
Extract
Данные извлекаются из внешних и внутренних источников: ERP, CRM, локальные документы, интернет, облачные системы, IoT-датчиков и других источников online streaming и пр. Затем передают их дальше для преобразований.
 |
Transform
Данные очищаются, фильтруются, группируются и агрегируются. Сырые данные преобразуются в готовый для анализа набор. Процедура требует понимания бизнес задач и наличия базовых знаний в области.
|
Load
Обработанные структурированные данные загружаются в DWH или целевые системы. Полученный набор данных используется конечными пользователями или является входным потоком к еще одному ETL-процессу.
Этапы процесса ELT
Extract
Данные извлекаются из внешних и внутренних источников: ERP, CRM, локальные документы, интернет, облачные системы, IoT-датчиков и других источников online streaming и пр.
|
Load
Необработанные данные загружаются в Data Lake или целевые системы. Затем данные преобразуются.
|
Transform
Данные очищаются, фильтруются, группируются и агрегируются. ELT-процесс может обрабатывать только ту часть данных, которая необходима для конкретной задачи.
КАК МЫ РАБОТАЕМ
1Первый звонок
2Техническое задание
Выделяем главные сложности проекта и способы их решения, обсуждаем технические детали, определяем сроки и стоимость.
3Коммерческое предложение
Обсуждаем окончательную цену проекта и тип партнерства. Подписываем документы.
4Консультация, прототипирование
Отдельно консультируем по технологиям и продуктам WorkFusion, UiPath, Automation Anywhere, разрабатываем прототипы решений по автоматизации и предоставляем услуги DevOps инженеров.
5Разработка и обучение
Процесс разработки прозрачный. Вы регулярно получаете отчеты о проделанной работе. После выполнения проекта мы обучаем ваших сотрудников пользоваться программой.
6Обслуживание и поддержка
Обсуждаем условия и стоимость обслуживания и поддержки системы.
СВЯЗАТЬСЯ С НАМИ
IBA Kz | ТОО «IBA (АЙ БИ ЭЙ) Казахстан»
- адрес Бизнес-центр «Ансар», ул. Сыганак, д. 43, 6 этаж, офис 604, Астана, 010000, Республика Казахстан
- телефон +7 7172 55 07 26
- email admin@ibagroup.kz